


Phòng thí nghiệm trí tuệ nhân tạo Google DeepMind đã công bố phát hành Gemma 3 270M, một trong những mô hình AI nhỏ nhất từng được tạo ra bởi Google với chỉ 270 triệu tham số. Mô hình này được thiết kế đặc biệt để chạy trên các thiết bị di động có công suất thấp như smartphone, tablet mà không cần kết nối mạng.
Điểm nổi bật nhất của Gemma 3 270M chính là khả năng tiết kiệm năng lượng vượt trội. Trong các thử nghiệm nội bộ sử dụng phiên bản INT4-quantized trên chip Pixel 9 Pro SoC, mô hình chỉ tiêu thụ 0,75% pin của thiết bị cho 25 cuộc hội thoại. Điều này khiến Gemma 3 270M trở thành lựa chọn lý tưởng cho các ứng dụng AI chạy trực tiếp trên thiết bị, đặc biệt trong những trường hợp ưu tiên tính riêng tư và khả năng hoạt động offline.

Omar Sanseviero, Kỹ sư Quan hệ Nhà phát triển AI của Google DeepMind, đã chia sẻ trên mạng xã hội X rằng Gemma 3 270M nhỏ đến mức có thể “chạy trên lò nướng bánh mì” hoặc trên các thiết bị nhỏ gọn như máy tính Raspberry Pi. Mô hình kết hợp 170 triệu “tham số nhúng” với 100 triệu “tham số khối transformer”, cho phép xử lý các token cụ thể và hiếm gặp.
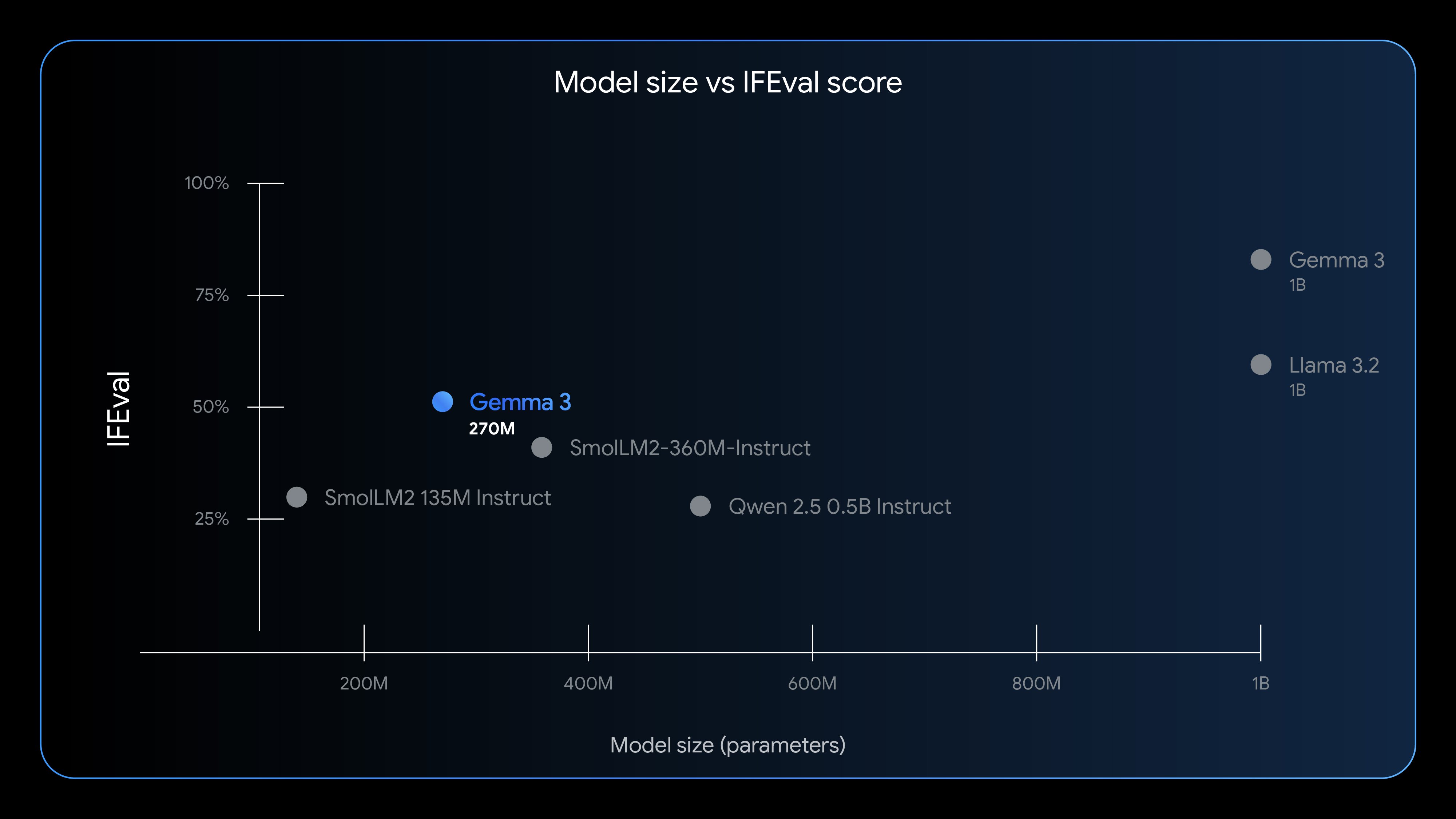
Mặc dù có kích thước nhỏ, Gemma 3 270M vẫn thể hiện khả năng ấn tượng trong các bài kiểm tra đánh giá. Trên bài kiểm tra IFEval – đo lường khả năng tuân theo hướng dẫn của mô hình, phiên bản instruction-tuned đạt điểm 51,2%. Con số này vượt xa các mô hình cùng kích thước như SmolLM2 135M Instruct và Qwen 2.5 0.5B Instruct.
Tuy nhiên, một số đối thủ cạnh tranh đã chỉ ra rằng Google bỏ sót một số mô hình trong so sánh. Startup Liquid AI đã phản hồi rằng mô hình LFM2-350M của họ, được ra mắt vào tháng 7, đạt điểm số 65,12% trên cùng bài kiểm tra với số lượng tham số tương đương.
Google nhấn mạnh rằng triết lý đằng sau Gemma 3 270M là việc chọn đúng công cụ cho đúng công việc thay vì chỉ tập trung vào kích thước mô hình. Đối với các tác vụ như phân tích cảm xúc, trích xuất thông tin, định tuyến truy vấn, tạo văn bản có cấu trúc, kiểm tra tuân thủ và viết sáng tạo, một mô hình nhỏ được tinh chỉnh có thể mang lại kết quả nhanh hơn và hiệu quả về chi phí hơn so với những mô hình lớn đa mục đích.
Công ty đã minh chứng cho khả năng này qua ví dụ hợp tác giữa Adaptive ML và SK Telecom. Bằng cách tinh chỉnh mô hình Gemma 3 4B cho kiểm duyệt nội dung đa ngôn ngữ, nhóm đã vượt qua hiệu suất của các hệ thống độc quyền lớn hơn nhiều.
Gemma 3 270M hiện có sẵn dưới hai phiên bản: pretrained và instruction-tuned, cùng với các checkpoint Quantization-Aware Trained (QAT) cho phép chạy ở độ chính xác INT4 với sự suy giảm hiệu suất tối thiểu. Mô hình được phát hành theo Gemma Terms of Use, cho phép sử dụng thương mại có trách nhiệm cho tất cả tổ chức bất kể quy mô.
Nhà phát triển có thể tải xuống mô hình từ Hugging Face, Ollama, Kaggle, LM Studio hoặc Docker. Mô hình cũng được hỗ trợ trên Vertex AI và các công cụ suy luận phổ biến như llama.cpp, Gemma.cpp, LiteRT, Keras và MLX.